
揭秘Ray-Ban Meta是如何诞生的|对话Meta智能眼镜产品负责人贾可南
揭秘Ray-Ban Meta是如何诞生的|对话Meta智能眼镜产品负责人贾可南11月26日,在GenAI Assembling与硅星人一起在硅谷Menlo Park举办的「AI机器人与可穿戴设备未来」的线下活动上,硅星人创始人兼CEO骆轶航与Meta AI/AR眼镜团队产品负责人贾可南进行了一场对话。
来自主题: AI资讯
9286 点击 2024-12-06 14:39
 搜索
搜索
11月26日,在GenAI Assembling与硅星人一起在硅谷Menlo Park举办的「AI机器人与可穿戴设备未来」的线下活动上,硅星人创始人兼CEO骆轶航与Meta AI/AR眼镜团队产品负责人贾可南进行了一场对话。

拥有「五感」的机器人离我们不远了。

最新消息,Meta 正在研发一款AI驱动的搜索引擎,旨在为使用 Meta AI 聊天机器人的用户提供关于时事的对话式回答,同时降低对谷歌和微软的依赖。

在OpenAI Sora的主要技术负责人跑去Google、多个报道指出OpenAI Sora在内部因质量问题而导致难产的节骨眼,Meta毫不客气发了它的视频模型“Movie Gen”,并直接用一个完整的评测体系宣告自己打败了Sora们。
Jiajun Xu : Meta AI科学家,专注大模型和智能眼镜开发。南加州大学博士,Linkedin Top AI Voice,畅销书作家。他的AI科普绘本AI for Babies (“宝宝的人工智能”系列,双语版刚在国内出版) 畅销硅谷,曾获得亚马逊儿童软件、编程新书榜榜首。
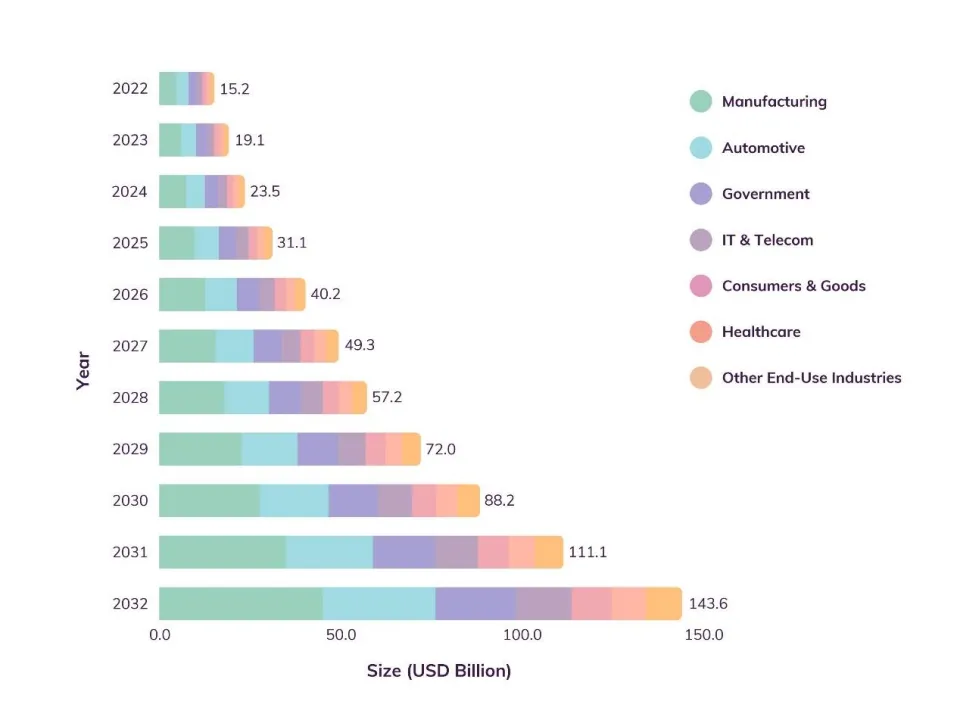
AI产品整体流量合计超过50亿,环比降低7.87%,Chat助手类产品流量占据57.74%。

Meta似乎也已经意识到,当下最好的选择是授人以渔。

Llama 3.1刚发布不久,Llama 4已完全投入训练中。 这几天,小扎在二季度财报会上称,Meta将用Llama 3的十倍计算量,训练下一代多模态Llama 4,预计在2025年发布。
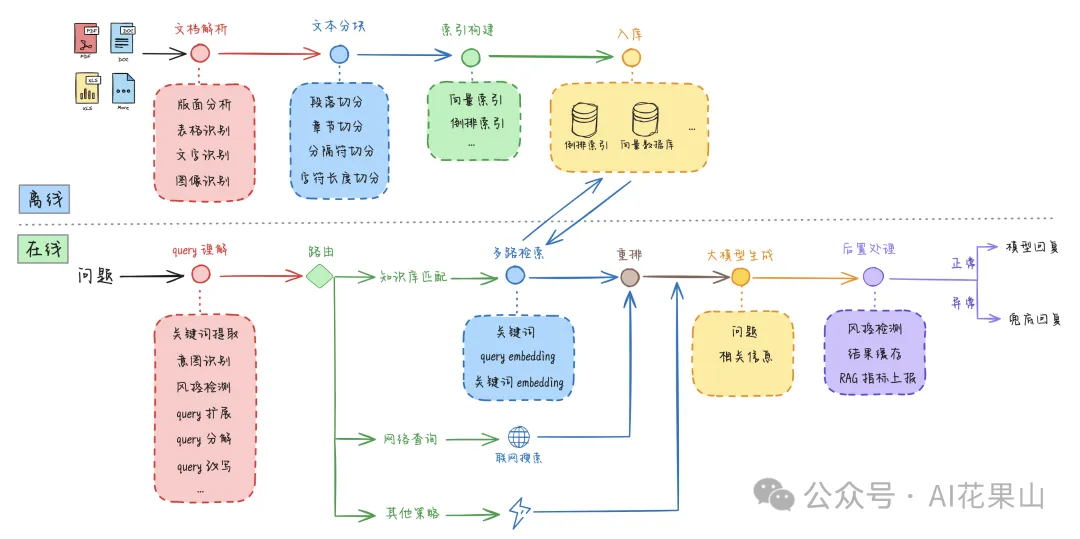
『RAG 高效应用指南』系列将就如何提高 RAG 系统性能进行深入探讨,提供一系列具体的方法和建议。同时读者也需要记住,提高 RAG 系统性能是一个持续的过程,需要不断地评估、优化和迭代。

还记得 Meta 的「分割一切模型」吗?这个模型在去年 4 月发布,被很多人认为是颠覆传统 CV 任务的研究。